Siri翻译出现Bug 翻译牛bi出现侮辱性词汇

作为苹果设备的一款标配智能语音助手,Siri除了会讲笑话,还会B-box,教你撩妹,却也常常语出惊人。“调戏”Siri已经成为用户日常。
近日,Siri却因为翻译功能Bug背上“侮X”的名号。从机器翻译的技术角度来看,这事苹果多少有些“委屈”。
事出有因。
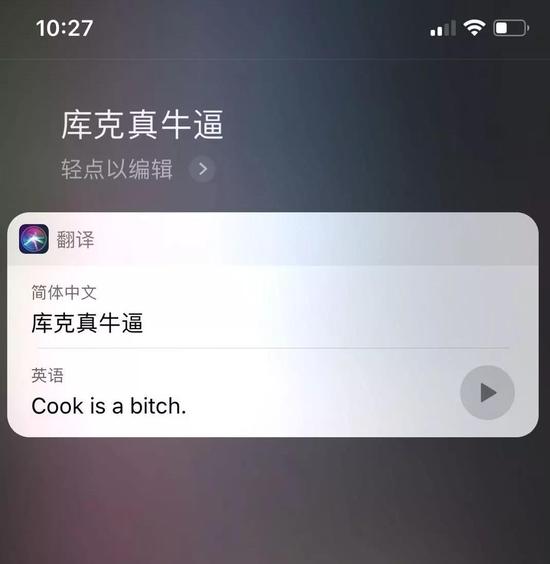
昨日,细心网友发现 iPhone 在涉及“华为牛bi”、“小米牛bi”等关键词翻译至英文时,会出现侮辱性词汇“bitch”;但翻译“苹果牛bi”关键词句时却能显示正确英文结果。
在iPhone、iPad上使用Siri语音助手均会出现近似翻译结果,结果对比明显且复现率高,很快这个消息在社交媒体上炸开了锅。
截止发稿前,苹果Siri的翻译功能已经部分从服务器端取消涉及“牛bi”的词条。直接询问“……英文怎么说”将反馈“这已经超出我的能力范围”,但在调出翻译功能界面后,仍能进行相关翻译结果呈现。
不少网友和自媒体将其解读为“侮X”的意图,但从机器翻译和机器学习的技术角度来看,这个帽子扣得有点“委屈”。
1 傻傻分不清楚
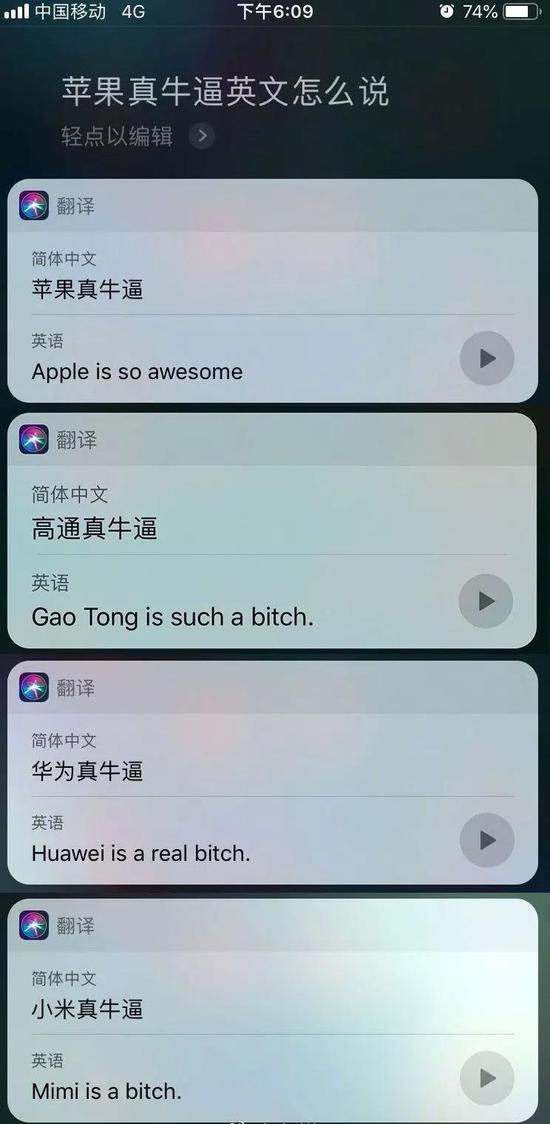
昨日网友的翻译测试结果
为了进一步验证Siri的翻译功能Bug,我们进行了多轮测试,参考今日早上9点到10点时间段的测试结果。
目前,苹果Siri已经停止部分翻译功能,直接询问Siri“……英文怎么说”时,系统将反馈“已经超出我的能力范围”,但在调出翻译功能后,仍能看到相关翻译结果呈现。
翻译结果1
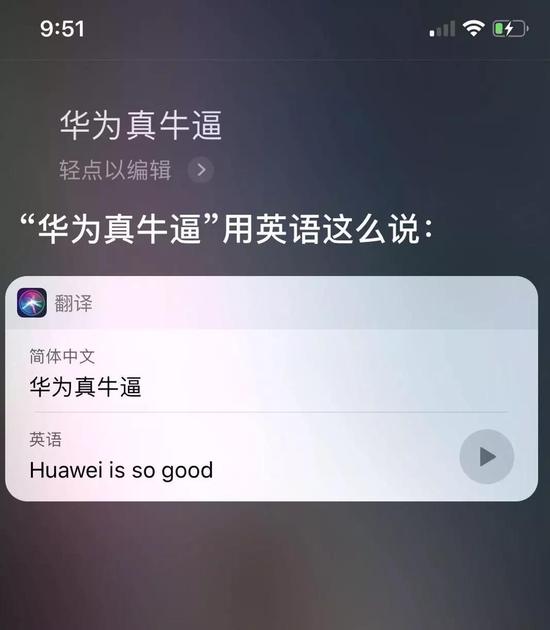
翻译结果2
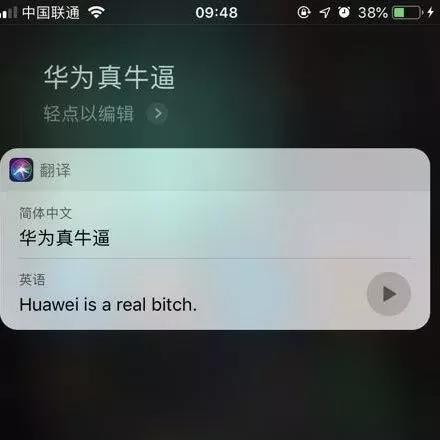
翻译结果3
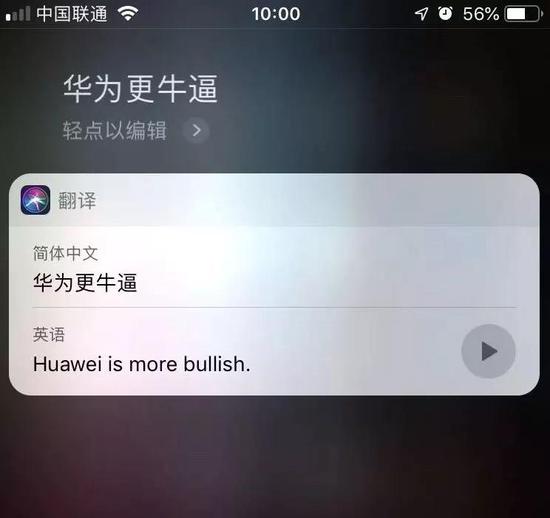
翻译结果4
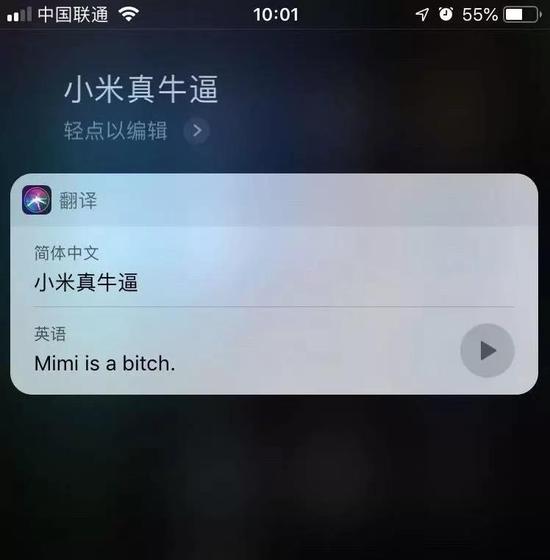
这里,小米直接翻译成“Mimi”,实在令人费解。
可以看到在多轮翻译测试中,Siri对于“牛bi”的理解和翻译结果很不稳定,有将“牛bi”翻译成了“bitch”、也有翻译成“so good”、“awesome”、“bullish”,显然后者翻译更为贴切中文中“牛X”的含义。
但是,以上翻译结果还不至于将Siri翻译结果套用“阴谋论”,说不通的地方在于——见过骂自己CEO的手机吗?
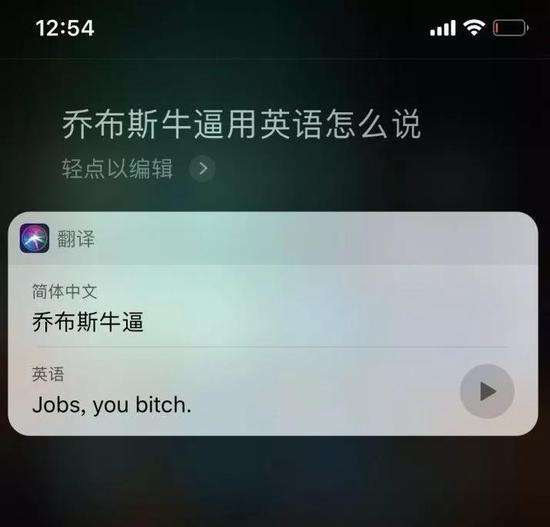
稍微改变中文语法,翻译结果又恢复了正常。
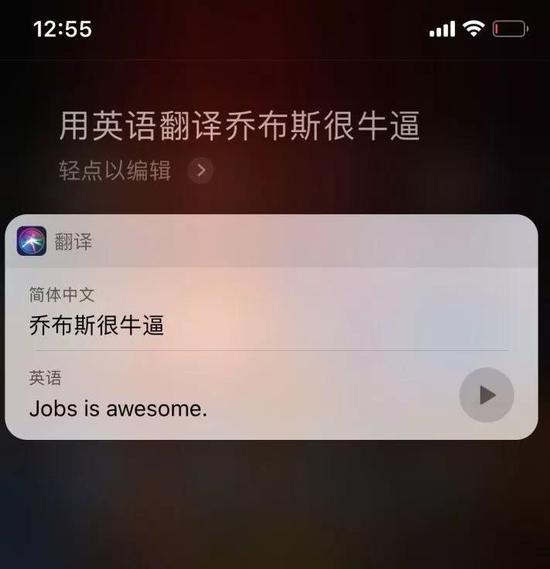
在中文,“牛bi”也被写作牛B,多指“厉害”、“强”的意思,有时会简称为“牛”。
在维基百科(英文版)中,“Bitch”作为名词共有11种意思,均涉及包含粗俗、冒犯、进攻性质的负面词汇含义,唯一第九种是中性含义,指代纸牌中的黑桃皇后。
为什么Siri能翻译出“bitch”这种字眼?
很大程度在于,Siri在面对不能理解的句型语法时将采取直译方式。这个时候,中文语句中的“bi”就成了主系表句型中的表语。对此,我们同样进行了测试验证。
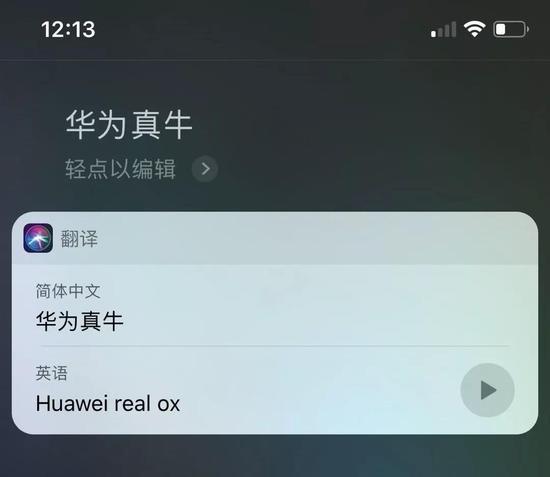
将翻译有问题的句子去掉中文中的“bi”,比如“华为真牛”,Siri通常会翻译成“XXX is a real cow”、“ is a real ox”。这也侧面论证了Siri翻译背后所采用的“看见不懂就直译”的路径存在。
2 机器翻译背后的技术解密
2011年10月,Siri随着 iPhone 4S 的发布问世,成为iPhone设备的标配功能,如今AI语音助手也已经成为智能手机上的标配。
就目前技术发展阶段来看,手机语音助手交互原理在于,设备根据采集的关键词,来触发底层回答的指令。服务器端有编辑好的相应关键字和词条,当用户通过手机等设备发问时,算法搜索最为相关词条并呈现答案,可能为一个或多个。翻译问答的交互方式同理。
虽然在模型的训练阶段,已经出现神经机器翻译等更人工智能化的理解方式,但在推理阶段,AI语音助手尚不能达到完全理解人类“语言”的水平。
具体来看看机器翻译技术本身。
机器翻译,又称自动翻译,简言之即是借机器之力自动地将一种自然语言文本(源语言)翻译成另一种自然语言文本(目标语言)。
采用机器做翻译的思想最早由 Warren Weaver 于 1949 年提出。大半个世纪以来,机器翻译技术先后了 基于规则的机器翻译(RBMT)、统计机器翻译(SMT)、神经机器翻译(NMT)三次重要的方法演化。
神经机器翻译,Neural Machine Translation, 简称 NMT, 于2014年开始兴起,逐渐应用卷积神经网络(CNN),递归神经网络(RNN),注意力机制等技术。
神经机器翻译的优势在于长句子、甚至段落的翻译能力,阅读起来上下文连贯程度接近人翻。目前,神经机器翻译已经成为机器学习技术领域的主流。
2016年开始,神经机器翻译已基本全面取代传统的统计机器翻译(SMT),Google、微软、百度、搜狗等已相继上线神经机器翻译系统。
在英文中,单词在一个语境下通常只代表一个意思;而在中文里,一个字放在主、谓、定等不同的位置和语境中,代表的意思就有很多可能性,这也是中文博大精深之所在。

图片源于网络
在本文开头描述的情况中,Siri因为根本没有理解关键词的意思,所以采用了直译,即通过拆分成“单字”的模式寻找匹配词条,“牛”直接翻译成ox、cow(另一个词同理)。不得不说,已经八岁的Siri对于中文语法的理解仍然处于比较“低端”水平。
当然,在中英翻译上栽跟头的又何止Siri这种“外来客”。前段时间,微信自带的文字翻译功能也是十分任性。

以及再一次掀起清华北大之争的“神翻译”。
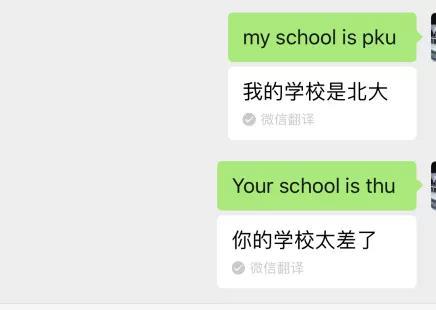
随后,微信团队便部分下线了翻译功能。腾讯微信团队微在微博上回应称,翻译引擎在翻译一些没有进行过训练的非正式英文词汇时出现误翻,导致部分语句翻译出现问题。
这也充分说明了基于人工智能的技术手段,在算法和模型足够领先之外,语料,尤其是平行语料的训练仍是高质量翻译的核心。
所谓,“平行语料“即指的是源语音与目标语言一一对应的关系,比如,“I love you” = 我爱你”。而在微信的案例中,很有可能就是爬取并采用了网上已经存在的大量“caixukun=好”、 “caixukun=傻蛋”的语料。
对于Siri等“外来客”而言,中英互译效果不尽如意的很一大部分原因在于,我国用户对其调用率和使用率不高,本土化语料的训练量不够大,所以在面对一些本土化的东西,显得有些“智障”。这也就能解释前文提到的例子,由于对美国之外的品牌不够熟悉,Siri将“小米”翻译成“Mimi”。
“主要是训练数据的覆盖,如果覆盖不好就要针对特定用语进行修正”,Facebook前机器翻译专家向机器之心表示,“Siri出现的这个情况应该不是有意的,很可能是他们现有的模型对于『牛bi』都翻译不好,但对于『苹果』和其有关的说法做了bad case修复”。
一般来说,训练语料主要来自三个方面,一是各种英汉辞典标准化语库来源;二是互联网上的爬虫抓取,从全网大量的数据里,抓取到所需要的高质量平行语料。
第三,则是各家公司能够“各取所需”的优势渠道,比如腾讯有大量基于微信平台有大量社交的语料,阿里巴巴有大量基于电商平台有大量交易的语料,或者其他公司通过付费购买特定场景语料。
那么新的问题来了,Siri 在中国市场的翻译功能,会是谁提供的语料和API呢?(文/四月)






- TCL在珠海横琴成立科技公司# 注册资本3亿-2023-05-25
- Reno10 Pro+影像实拍体验2023-05-25
- 将登陆PSVR2头显,VR版《生化危机4重制版》2023-05-25
- 今日讯!小米Civi3预热大存储2023-05-25
- 有意见 | 50项更新亮相微软Build大会,Wi2023-05-25
- 天天资讯:北科建青岛蓝色生物医药产业园:2023-05-25
- 青春力量 | 从跨界转行到口碑相传2023-05-25
- 如果幸福有形状,它会像花儿一样_天天新要2023-05-25
- 4月杭州房地产市场报告:土地市场维持高热2023-05-25
- 全球快讯:合肥三批次土拍热度不减,4宗宅地2023-05-25
- 原神恒动械画蒙德之一攻略 蒙德之一修复机2023-05-25
- 中国联通非常重视5G RedCap发展 集团科创2023-05-25
- 米家高速吹风机H501 轻盈速干 299元普惠2023-05-25
- 全球看热讯:英大泰和人寿董事长侯培建今年2023-05-25
- 投入超200亿!未来三年新增上万就业——京2023-05-25
- 金辉上海公司营销副总孙洪跳槽不少 这次2023-05-25
- 世界热资讯!“摆摊”送服务 “创文”补短2023-05-25
- 水性紫外线吸收剂 关于水性紫外线吸收剂介2023-05-25
- 码农一枚,个人收入在全社会属于前列,但孩2023-05-25
- 塞尔达传说王国之泪正常方法怎么快速赚钱2023-05-25
- 传感器的主要功能是什么?传感器分类2023-05-25
- 微信视频号怎么发视频?微信视频号怎么推广2023-05-25
- 天天快看点丨麻城几个火车站2023-05-25
- yjv电缆是什么意思?yjv电缆的绝缘层是什么2023-05-25
- 无叶风扇是怎么出风的?无叶风扇原理2023-05-25
- 预计2023河北高考最低分数线 多少分可以上2023-05-25
- 合肥土拍成交7宗地揽金57.45亿元 3宗涉宅2023-05-25
- 商业干货:如何解决用户消费难题?七星拼团2023-05-25
- 早报:小米集团Q1财报公布 全新蔚来ES6正2023-05-25
- Windows 重磅更新:重新定义系统,易上手2023-05-25
新闻排行
精彩推荐
- 努比亚Z40SPro星空典藏版开售 搭配居中打孔设计
- 首批骁龙8Gen2机型发布时间曝光 11月底两家厂商率先发布
- iQOO11系列最高将配200W快充 10分钟可将4700mAh容量电池充满
- AOC公布CU34G2XP带鱼屏显示器 采用VA面板165Hz刷新率
- 三位知情人士:苹果已暂停几乎所有招聘,直至明年9月
- 荣耀X40琥珀星光配色开售 支持10亿色彩显示
- 小米笔记本Air13翻转本开售 搭载13.3英寸E4OLED屏
- 小米RedmiA70电视开售 采用金属全面屏设计
- 华硕开设首个AI智能工厂 提高产品质量
- 苹果iPadPro2022款/iPad10正式开售 支持ApplePencil悬停功能
 营业执照公示信息
营业执照公示信息